
Una de mis tareas en mi trabajo es mantener la base de datos de una de las aplicaciones de la organización, el RDBMS es MySQL en su versión 5.0 comunity.
Accidentalemte se borro una de las tablas en dicha base y obviamente me pidieron que recupere la tabla del backup, yo muy feliz fuí a buscar los backup's para recuperar la tabla y me encuentro con que el último backup completo hera del 25 de feberero y solo con ciertos incrementales (binlogs de mysql), la mayoría del las copias fallaron debido a que la unidad donde relizaba los respaldos se ocupaba para otras cuestiones y aveces no contaba con el espacio necesario.
Al darme cuenta de lo sucedido empezé a sudar como testigo falso, dado que nunca me puse a controlar si los backups se realizaban adecuadamente, mea culpa. Empezé a pensar como podía recuperar la información e inmediatamente fuí a ver si los binlog seguían en el servidor de producción, y sí efectivamente estaban todos y completos.
Fue ahí cuando decidí recuperar la base completa al 25 de febrero y aplicar los binlogs hasta el día de la catastrofe, 18 de abril.
Descomprimí el backup completo de la base, obtenido mediante un msyqldump, y el mismo pesaba 14 GB, esto es debido a que en el mismo estaban todas las bases de datos de esa instancia y yo solo quería una de ellas a la que llamaré XXX.
Probe tratar de editar el archivo con vi, nano, kedit, gedit pero ninguno podía abrirlo. Sin saber que hacer para extraer solo la base XXX del backup se me ocurrió utilizar la consola de linux. Lo primero que hice fue ver las lineas donde empezaban las bases, como?, fácil, en el dump de mysql la primera instrucción es CREATE DATABASE, por ello realizé un grep con dicha expresión sobre el archivo e indique me muestre los números de líneas.
grep -n "CREATE DATABASE" bkp-25-02-2008.sql
El mismo me arrojo algo así
10 CREATE DATABASE ....
1400 CREATE DATABASE ....
23456 CREATE DATABASE XXX
45234 CREATE DATABASE ...
....
Una vez que tenía la línea donde empezaba y terminaba el dumpeo de la base XXX, realizé un head hasta la línea 45234 para obtener la primera parte y luego apliqué un tail desde el final a la línea 21778 (45234 - 23456). El comando quedo algo así
#head -n 45234 25022008.sql |tail -n 21778 > recorte.sql
Una vez que termino el archivo resultante quedo de 2.7 GB. En una base de datos limpia cargue el dumpeo recortado.
mysql -u root -p < recorte.sql
Al finalizar tenía la base lista al 25 de febrero y solo restaba aplicar los binlogs de cada día. Como heran varios decidí hacer un pequeño script en python para que los procese de a uno. Básicamente hera un bucle for que iba desde el número de binlog incial (1828) al final (1976), este transforma cada bin log en un script sql (mysqlbinlog) y lo deja en un archivo temporal el cual es importado a la base.
#!/usr/bin/python
import os for i in range(1828,1976):
print i
file = 'mysql-bin.00%s' % str(i)
os.popen('rm tmp.sql')
os.popen('mysqlbinlog --database=XXX %s > tmp.sql' % file)
os.popen('mysql -u root --password=lapass <>
La primera vez que lo probe arrojo unos errores, lo primero que pense es que continuaba la importación después de el error pero había sido que no, la importación se corta directamente en el punto de error, en consecuencia faltaba muchisima información.
Al final de todo y después de varias pruebas tuve la suerte de poder recuperar la información.
Esta fue una linda experiencia para contar pero no para vivirla, todo esto se hubiese solucionado siendo un poco cuidadoso en chequear los backups generados automáticamente.
lunes, 28 de abril de 2008
jueves, 24 de abril de 2008
Debian y ACPI

Hace unos días instale en mi laptop Debian sacando mi querido gentoo el cual estaba instalado hace 2 años prácticamente. La razón del cambio, bueno básicamente en mi trabajo todos los servers tienen debian, por ende quería estar metido a full con esa plataforma, de tal manera poder adquirir buena experiencia para resolver los problemas mas rápidamente.
adicionales al kernel para que arranque debidamente en mi Después de haber terminado la instalación básica, solo sistema base, comencé a instalar los programas que generalmente uso, al terminar quiero apagar la maquina como siempre lo hago, presionando el botón de power, y la maquina no se apago corriendo la secuencia de apagado normal sino que directamente se apago, es decir fue un apagado forzado.
Sin dudar me dí cuenta que hera problema del ACPI, el cual probablemente se me deshabilito cuando comencé la instalación del sistema y pase parámetros al kernel para lanzar la instalación (noapicnolapic vga=711).
La solución fue instalar los paquetes para acpi :
apt-get install acpi acpid acpitool laptop-mode-tools
Y por último pasar el parámetro acpi al kernel, editando el archivo /boot/grub/menu.lst, en la línea del kernel que utilizan deben añadir acpi=force.
title Debian GNU/Linux, kernel 2.6.18-5-486
root (hd0,0)
kernel /boot/vmlinuz-2.6.18-5-486 root=/dev/hda1 ro vga=771 acpi=force noagp
initrd /boot/initrd.img-2.6.18-5-486
savedefault
Después de reiniciar las funciones de ACPI funcionaron de mil maravillas.
martes, 22 de abril de 2008
RAID on linux
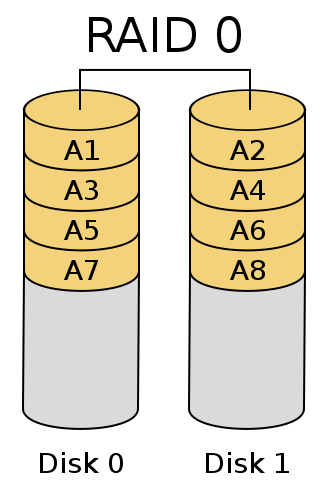
En mi casa tengo mi vieja PC Pentium 3 de 800 mhz con 512MB de ram, la misma cuenta con 2 discos de 20 GB y uno de 40 GB. Dicha pc cumple la función de file server hogareño, access point casero (me salía más barato que comprarme uno), servidor LAMP en el cual tengo montada mi página personal (http://www.casiva.com.ar), servidor de descargas y host para la maquina virtual con windows que utiliza mi padre. El sistema operativo base que tengo instalado es Debian etch.
La cuestión es que la máquina estaba pidiendo ayuda a los gritos, básicamente se arrastraba, así que me puse a pensar que podía hacer para mejorar su performance sin gastar un centavo lo que me llevo a decidir montar un RAID 0 entre los discos de 20 GB.
Para ello realizé una instalación nueva, dado que reparticioné los discos creando dos particiones de 20GB en los discos elegidos. La creación del RAID la realizé mediante el instalador del sistema Debian, allí seleccione las particiones señalando que serían parte de un RAID, por ultimo creé un dispositivo RAID mediante el mismo instalador, al finalizar me apareció en el asistente de particionado del instalador de Debian una unidad md0, la que representaba al RAID recientemente creado, elegí dicha unidad como punto de montaje de la raíz y continué con los pasos de instalador.
Después de una semana de testeo del RAID no tengo de que quejarme, se comporta de mil maravillas y logre alcanzar un rendimiento mucho más aceptable. No realizé benchmarkings para presentarles los hechos con números y que saquen sus propias conclusiones, pero con el simple uso del sistema uno se da cuenta de la mejoría.
En conclusión, es una buena técnica de optimización que no nos lleva a gastar dinero. Recomiendo que lo prueben.
Mas info:
Wikipedia : Tipos de Raid
viernes, 18 de abril de 2008
MySQL - Ahora se cierra el circulo

Acabo de enterarme que Sun decidió empezar a cerrar más aún el código de MySQL, cosa que no me sorprende para nada dado que siempre avise a todo el mundo de que esto pasaría y pocos me escucharon.
Según tengo entendido una de las carácteristicas más interesantes que no estarán disponibles en la versión de la comunidad es la de backup-online (característica muy necesitada para cualquier entorno de producción del tipo 24/7).
Muy interesante a todo esto es la reflexión de Facundo Arena, muy sabía por cierto.
viernes, 4 de abril de 2008
Inocente Palomita

Con respecto al post anterior les cuento que me engañaron como a una vil mucama paraguaya, todo el proyecto Virgle no era mas que una broma por el día de los inocentes.
Me vengare google!
miércoles, 2 de abril de 2008
Vamos a Marte!
Esta gente de Google no para de sorprenderme, ahora se les ocurrió colonizar marte, si si colonizar marte.
El nombre del nuevo proyecto es Virgle, dado que la operación se realizará en conjunto con la empresa Virgin y Google.
La idea es comenzar a enviar equipos, herramientas y provisiones a marte, posteriormente enviar a un equipo inicial de colonizadores para empezar a crear los elementos necesarios para el nuevo hábitat.
Parece un poco descavellada la idea pero esta bueno que alguien se ponga las pilas sobre este tema, no puede ser que en el siglo 21 todavía estemos tratando de hacer caminar un robot y que la innovación más grosa hasta el momento sea el microchip, vamos genios a trabajar!
Visitando el site del proyecto también vi como cosa interesante que el planeta será Open Source, es decir el proyecto liberará todo el conocimiento que adquieran tratando de realizar su objetivo a todo el mundo, de tal manera de promover la investigación.
Aquellos interesados en ser parte de los pioneros pueden llenar el formulario de subscripción. (Me mataron las preguntas), igualmente el primer viaje no esta pensado para hasta dentro de 20 años (yo ya estaría muy viejo y loco para ir).
Suscribirse a:
Comentarios (Atom)
